Articles
Как следует из названия статьи, сегодня мы займёмся некой функцией, которая включена по умолчанию на большинстве платформ Cisco IOS. Преследуемых целей две: встать на грабли, а потом выяснить их модель (производитель уже известен).
Топология лабы представлена ниже:
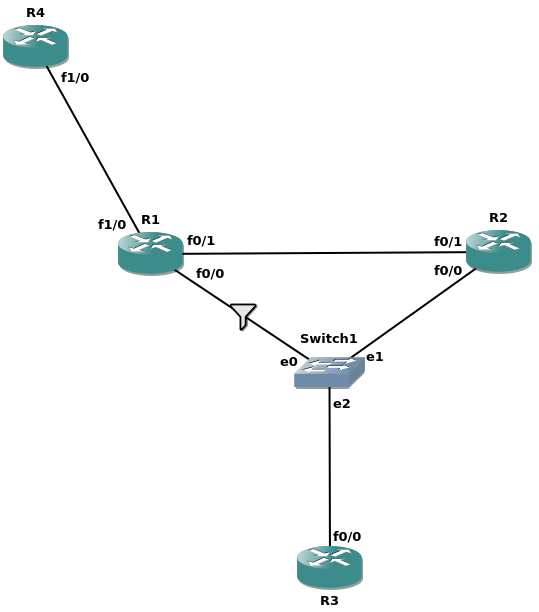
Все маршрутизаторы на схеме – это Cisco 7200 с прошивкой 15.2(4)M11. R3 выполняет роль конечного устройства (например, сервера), а R4 притворяется интернетом. Фильтр для соединения R1-Switch1 вносит дополнительную задержку для проходящего через него трафика. Актуальные выдержки из настроек маршрутизаторов:
R4(config)# interface Loopback0
R4(config-if)# ip address 4.4.4.4 255.255.255.255
R4(config)# interface FastEthernet1/0
R4(config-if)# ip address 192.168.14.4 255.255.255.0
R4(config)# router eigrp 1
R4(config-router)# network 0.0.0.0
R3(config)# interface FastEthernet0/0
R3(config-if)# ip address 192.168.0.3 255.255.255.0
R3(config)# ip route 0.0.0.0 0.0.0.0 192.168.0.1
R2(config)# interface FastEthernet0/0
R2(config-if)# ip address 192.168.0.2 255.255.255.0
R2(config)# interface FastEthernet0/1
R2(config-if)# ip address 192.168.12.2 255.255.255.0
R2(config)# router eigrp 1
R2(config-router)# network 0.0.0.0
R2(config)# interface FastEthernet0/0
R2(config-if)# ip address 192.168.0.1 255.255.255.0
R2(config)# interface FastEthernet0/1
R2(config-if)# ip address 192.168.12.1 255.255.255.0
R4(config)# interface FastEthernet1/0
R4(config-if)# ip address 192.168.14.1 255.255.255.0
R2(config)# router eigrp 1
R2(config-router)# network 0.0.0.0
В неопределённый момент в прошлом R2 был выключен, и сейчас его вернули снова в строй. Инженер наблюдает большой поток однонаправленного трафика из интернета в сторону R3, причём этот трафик чувствителен к задержкам. Канал между R1 и Switch1 оказывается перегружен, поэтому инженер принимает решение перенаправить проблемный поток через R2. Обратный трафик в сторону интернета незначителен, так что R1 остаётся на время единственным шлюзом по умолчанию.
Самый очевидный способ завернуть трафик для R3 в сторону R2 – статический маршрут на R1:
- R1 шлёт трафик для R3 через R2 согласно /32 маршруту;
- R2 использует локальный /24 маршрут, чтобы передать трафик R3.
Сказано – сделано:
R1(config)# ip route 192.168.0.3 255.255.255.255 192.168.12.2
Однако, как только инженер внёс необходимые изменения, R3 полностью пропал с радаров:
R3#ping 4.4.4.4
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 4.4.4.4, timeout is 2 seconds:
..…
Success rate is 0 percent (0/5)
R4#ping 192.168.0.3 source loopback 0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.0.3, timeout is 2 seconds:
Packet sent with a source address of 4.4.4.4
.....
Success rate is 0 percent (0/5)
Ближайшие 2 маршрутизатора, R1 и R2, также недоступны:
R3#ping 192.168.0.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.0.1, timeout is 2 seconds:
.....
Success rate is 0 percent (0/5)
R3#ping 192.168.0.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.0.2, timeout is 2 seconds:
.....
Success rate is 0 percent (0/5)
Никаких проблем на Switch1 не зафиксировано, CAM-таблица содержит в себе корректную информацию. Запустим traceroute на R3 и R4:
R3#traceroute 4.4.4.4
Type escape sequence to abort.
Tracing the route to 4.4.4.4
VRF info: (vrf in name/id, vrf out name/id)
1 * * *
2 * * *
3 * * *
<output trimmed>
R4#traceroute 192.168.0.3 source loopback 0
Type escape sequence to abort.
Tracing the route to 192.168.0.3
VRF info: (vrf in name/id, vrf out name/id)
1 192.168.14.1 16 msec 12 msec 8 msec
2 192.168.12.2 20 msec 20 msec 20 msec
3 192.168.0.1 1388 msec 1300 msec 1296 msec
4 192.168.12.2 1420 msec 1296 msec 1300 msec
5 192.168.0.1 2696 msec 2604 msec 2696 msec
6 192.168.12.2 2612 msec 2704 msec 2696 msec
<output trimmed>
Очевидно, что в сеть прокралась петля – R2 сошёл с ума и шлёт трафик обратно на R1. Каких-либо конкретных симптомов, впрочем, обнаружить не удаётся; IP адрес попадает в connected сеть, R2 выполняет ARP-запрос и обрабатывает последующий ARP-ответ:
R2#sho ip cef 192.168.0.3
192.168.0.3/32
attached to FastEthernet0/0
R2#sho adjacency 192.168.0.3
Protocol Interface Address
IP FastEthernet0/0 192.168.0.3(7)
Маршрутизация в полном порядке, поэтому займёмся последней милей:
R2#sho ip arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 192.168.0.1 53 ca01.221b.0008 ARPA FastEthernet0/0
Internet 192.168.0.2 - ca02.224b.0008 ARPA FastEthernet0/0
Internet 192.168.0.3 54 ca01.221b.0008 ARPA FastEthernet0/0
Internet 192.168.12.1 55 ca01.221b.0006 ARPA FastEthernet0/1
Internet 192.168.12.2 - ca02.224b.0006 ARPA FastEthernet0/1
Коллеги, видите ли вы что-то странное? Всё верно, 192.168.0.1 и 192.168.0.3 соответствуют одному и тому же MAC адресу, ca01.221b.0008, который принадлежит R1. Запахло жуками, поэтому попробуем очистить ARP-таблицу в надежде, что проблема исчерпает себя:
R2#clear arp
R2#sho ip arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 192.168.0.1 0 ca01.221b.0008 ARPA FastEthernet0/0
Internet 192.168.0.2 - ca02.224b.0008 ARPA FastEthernet0/0
Internet 192.168.0.3 0 ca01.221b.0008 ARPA FastEthernet0/0
Internet 192.168.12.1 0 ca01.221b.0006 ARPA FastEthernet0/1
Internet 192.168.12.2 - ca02.224b.0006 ARPA FastEthernet0/1
Слишком настойчивый баг, не находите? Напоминание для тех, кто ожидал увидеть пустую таблицу, а не нулевой возраст записей: при очистке ARP-таблицы IOS шлёт unicast (да-да) ARP запросы, чтобы обновить соответствующие записи. Выключение и включение интерфейса на R2, впрочем, даёт лучик надежды:
R4#ping 192.168.0.3 source loopback 0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.0.3, timeout is 2 seconds:
Packet sent with a source address of 4.4.4.4
...!.
Похоже, что изначально трафик ведёт себя так, как и было задумано; однако впоследствии что-то нарушает желаемый порядок вещей, переписывая на R2 ARP запись для R3 на MAC адрес, принадлежащий R1.
Помните настройку по умолчанию, связанную с ARP, которую обычно рекомендуют отключать? Да, речь о Proxy ARP, который мог предоставить связность для устройств без шлюза по умолчанию или с некорректной настройкой маски подсети:
Since the router knows that the target address (172.16.20.200) is on another subnet and can reach Host D, it replies with its own MAC address to Host A.
Вольный перевод:
Поскольку маршрутизатор знает, что целевой адрес (172.16.20.200) находится в другой подсети, он отвечает собственным MAC адресом на запрос Host A.
Впрочем, это лишь первая половина загадки; вторая относится к тому, как положено обрабатывать ARP пакеты. Согласно RFC826, сообщения ARP могут быть использованы для двух целей:
- обновление существующей ARP записи;
- создание новой ARP записи на том устройстве, которое послало ARP запрос.
В нашем случае это означает, что ARP ответ R1 от лица R3 не может создать новую запись в ARP таблице на R2; к сожалению, это также означает, что R1 может «обновить» соответствующую запись. Получается следующая последовательность событий:
- R2 получает пакет, предназначенный для R3, но не находит нужной ARP записи;
- R2 посылает ARP запрос и получает корректный ARP ответ от R3, что проявляется в краткосрочной связности для R3;
- поскольку ARP запрос является широковещательным, R1 также получает ARP запрос от R2 после определённой задержки на канале R1-Switch1;
- в таблице маршрутизации на R1 присутствует 192.168.0.3/32, что активирует ARP ответ в рамках Proxy ARP, т.к. R1 считает, что 192.168.0.3 находится в другой подсети;
- ARP ответ от R1 достигает R2 позже, чем ARP ответ от R3, благополучно переписывая ARP запись на R2 для R3, используя MAC адрес R1;
- Петля маршрутизации, приятно познакомиться.
Проверим, что дело действительно в Proxy ARP и его отключение разрешит проблему:
R1(config)#int f0/0
R1(config-if)#no ip proxy-arp
R2#clear arp
R4#ping 192.168.0.3 source loopback 0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.0.3, timeout is 2 seconds:
Packet sent with a source address of 4.4.4.4
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 116/120/124 ms
R2#sho ip arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 192.168.0.1 1 ca01.221b.0008 ARPA FastEthernet0/0
Internet 192.168.0.2 - ca02.224b.0008 ARPA FastEthernet0/0
Internet 192.168.0.3 1 ca03.225a.0008 ARPA FastEthernet0/0
Internet 192.168.12.1 1 ca01.221b.0006 ARPA FastEthernet0/1
Internet 192.168.12.2 - ca02.224b.0006 ARPA FastEthernet0/1
Наконец, решение в виде статического маршрута заработало. Может показаться, что причина такого некорректного поведения – неисправный канал R1-Switch1 и что в современной сети рассмотренная проблема невозможна. Однако если учесть длину L2 сегмента и задержки, вносимые оборудованием, становится очевидно, что ARP ответ от Proxy ARP может случайным образом прийти позже корректного ARP ответа, что приведёт к недоступности соответствующего хоста. Современные сети действительно построены без опоры на асимметричную маршрутизацию на шлюзе по умолчанию. Однако вряд ли даже в таких сетях кто-то сможет дать гарантию, что все возможные сценарии учтены и не придётся впоследствии вносить изменения, противоречащие, хотя бы и на непродолжительное время, общему духу симметричной маршрутизации. Вывод: стоит отключить Proxy ARP, если он не выполняет критических задач.
Статья вдохновлена книгой Routing TCP/IP, Volume 1, 2nd Edition, особенно разделом про отладку статических маршрутов.
Disclaimer: только для гиков; устаревшая технология; статья в режиме “just for fun”.
Разобравшись со смузи и подворотами, можем приступить к сути статьи – BGP synchronization в связке с OSPF. Стоит сразу отметить, что технология BGP sync действительно не является актуальной уже лет дцать и многие современные платформы даже не поддерживают её. В своё время я наткнулся на довольно занятное описание одной особенности BGP sync при использовании с OSPF в качестве IGP и хотел бы поделиться полученным опытом.
Впрочем, займёмся лабой; чем меньше топология, тем проще её анализировать:
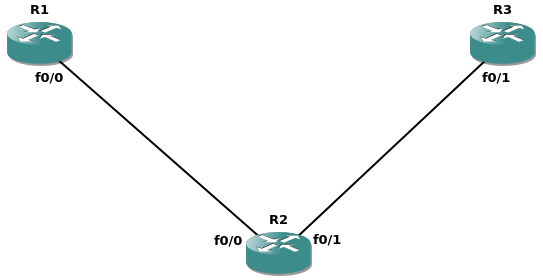
На данный момент настроена лишь базовая адресация:
R1(config)#int f0/0
R1(config-if)#ip address 192.168.12.1 255.255.255.0
R1(config-if)#no shutdown
R2(config)#int f0/0
R2(config-if)#ip address 192.168.12.2 255.255.255.0
R2(config-if)#no shutdown
R2(config)#int f0/1
R2(config-if)#ip address 192.168.23.2 255.255.255.0
R2(config-if)#no shutdown
R3(config)#int f0/1
R3(config-if)#ip address 192.168.23.3 255.255.255.0
R3(config-if)#no shutdown
Включим BGP вместе с synchronization на R1 и R3:
R1(config)#router bgp 1
R1(config-router)#synchronization
R1(config-router)#neighbor 192.168.23.3 remote 1
R3(config)#router bgp 1
R3(config-router)#synchronization
R3(config-router)#neighbor 192.168.12.1 remote 1
Самое время добавить щепотку тестовых маршрутов. Создадим loopback 0 на R1 с адресом 1.1.1.1/32 и добавим его в BGP:
R1(config)#interface Loopback 0
R1(config-if)#ip address 1.1.1.1 255.255.255.255
R1(config)#router bgp 1
R1(config-router)#network 1.1.1.1 mask 255.255.255.255
Теперь можно включить в схеме OSPF, чтобы обеспечить связность между BGP маршрутизаторами:
R1(config)#int f0/0
R1(config-if)#ip ospf 1 area 0
R2(config)#router ospf 1
R2(config-router)#network 0.0.0.0 255.255.255.255 area 0
R3(config)#int f0/1
R3(config-if)#ip ospf 1 area 0
На данный момент маршрут должен быть в BGP RIB на R3, однако он не может быть установлен в global RIB вследствие BGP sync:
R3#sho ip bgp 1.1.1.1/32
BGP routing table entry for 1.1.1.1/32, version 0
Paths: (1 available, no best path)
Not advertised to any peer
Refresh Epoch 1
Local
192.168.12.1 (metric 2) from 192.168.12.1 (192.168.12.1)
Origin IGP, metric 0, localpref 100, valid, internal, not synchronized
R3#sho ip bgp
<output omitted>
Синхронизация в своё время была призвана защитить сеть от возникновения дыр маршрутизации, когда маршрут известен на оконечных BGP маршрутизаторах, но не на транзитных устройствах. Исправим возникшую “проблему”, добавив 1.1.1.1/32 в сеть OSPF c помощью переноса этого маршрута из BGP:
R1(config)#router ospf 1
R1(config-router)#redistribute bgp 1 subnets
На данный момент iBGP маршрут известен и по BGP, и по OSPF, поэтому он должен пройти проверку BGP sync, однако по какой-то причине 1.1.1.1/32 до сих пор находится в состоянии not synchronized:
R3#sho ip bgp
<output omitted>
R3# sho ip bgp 1.1.1.1/32
BGP routing table entry for 1.1.1.1/32, version 3
Paths: (1 available, no best path)
Not advertised to any peer
Refresh Epoch 1
Local
192.168.12.1 (metric 2) from 192.168.12.1 (192.168.12.1)
Origin IGP, metric 0, localpref 100, valid, internal, not synchronized
Мне не удалось найти сколько-то внятного дебага, который пролил бы свет на причину этого поведения. Впрочем, существует довольно любопытная заметка по отладке BGP:
If BGP synchronization is enabled, there must be a match for the prefix in the IP routing table in order for an internal BGP (iBGP) path to be considered a valid path. <...> If the matching route is learned from an Open Shortest Path First (OSPF) neighbor, its OSPF router ID must match the BGP router ID of the iBGP neighbor.
Вольный перевод
Если функция BGP synchronization включена, должно быть соответствие между маршрутом в базе данных BGP и таблице маршрутизации, чтобы такой маршрут, полученный по iBGP, считался корректным. <...> В случае, если маршрут известен по OSPF, то OSPF RID соседа должен совпадать с RID соседа iBGP.
Мне кажется, что было бы несколько точнее сформулировать вышеизложенную мысль следующим образом: BGP RID должен совпадать с OSPF RID внутри соответствующего LSA5, в нашем случае – 1.1.1.1/32. Разница между двумя формулировками заключается в том, что iBGP сосед не обязан быть OSPF соседом. Также стоит отметить, что в силу применения BGP sync на стыке транзитной и внешней сетей эта функция учитывает только LSA5, внутренние OSPF маршруты при этом она игнорирует (я оставлю проверку этого факта на совести внимательного читателя).
Сможете, вооружившись этим знанием, определить RID для OSPF и BGP? Если вы полагаете, что это 1.1.1.1/32 для OSPF и 192.168.12.1 для BGP – вы угадали:
R3#sho ip bgp neighbors | i ID
BGP version 4, remote router ID 192.168.12.1
R3#sho ip ospf database external | i Advertising
Advertising Router: 1.1.1.1
Поскольку мы создали loopback после инициализации процесса BGP, последний использовал наименьший IP адрес на физических интерфейсах в качестве RID; что касается OSPF, то он уже мог выбрать RID среди интерфейсов типа loopback. Проверим, что корень проблемы - это несовпадение RID:
R1(config)#router bgp 1
R1(config-router)#bgp router-id 1.1.1.1
R3#sho ip bgp
<output omitted>
R3#sho ip bgp nei | i ID
BGP version 4, remote router ID 1.1.1.1
R3#sho ip ospf database external | i Advertising
Advertising Router: 1.1.1.1
Как мы видим, теперь маршрут является корректным с точки зрения BGP, и его можно передавать дальше.
BGP synchronization, хоть и кошмарил раньше кандидатов на CCIE, теперь ушёл на покой, так что эта тема сейчас находится под грифом “just for fun” в библиотеке сетевых знаний.
DMVPN является известным решением для построения топологий hub&spoke. В ряде случаев может понадобиться поддержка изолированной передачи трафика различных клиентов. Конечно, можно построить DMVPN туннель в каждом VRF; однако в реальной жизни такой подход не является достаточно масштабируемым. В такой ситуации на ум приходит MPLS, который зарекомендовал себя в корпоративных и провайдерских сетях.
GRE поддерживает инкапсуляцию различных PDU, в том числе и MPLS, поэтому, на первый взгляд, не должно возникнуть проблем на уровне передачи трафика. С управляющими протоколами, однако, ситуация обстоит несколько сложнее. LDP и RSVP должны установить соседство перед тем, как обменяться какими-либо данными. Масштабируемость этих протоколов обусловлена использованием мультикаста для обнаружения соседей и обмена с ними необходимыми параметрами протокола. Ручная настройка LDP/RSVP соседства в DMVPN сведёт на нет масштабируемость, поэтому такой сценарий статья не рассматривает. Использование же мультикаста ограничивает функциональность решения, поскольку spoke могут обмениваться такими сообщениями только с hub, что исключает наличие spoke-to-spoke связности с использованием MPLS.
Впрочем, существует третье решение, которое является достаточно масштабируемым, а также способно обеспечить MPLS-связность spoke-узлов между собой – это BGP labeled unicast (BGP LU). Существует несколько способов превратить spoke-маршрутизатор в PE (например, первый вариант – отправить пакет с VPN меткой напрямую другому spoke, аналог второй фазы DMVPN; второй вариант – hub принимает непосредственное участие в передаче пакета внутри VRF, выполняя перенаправление пакета, как в третьей фазе DMVPN); однако в определённых случаях может возникнуть необходимость разместить PE за spoke.
Как обычно, соберём лабу и итеративно построим рабочее решение. Ниже приведена используемая топология в рамках рассмотрения 2547oDMVPN:
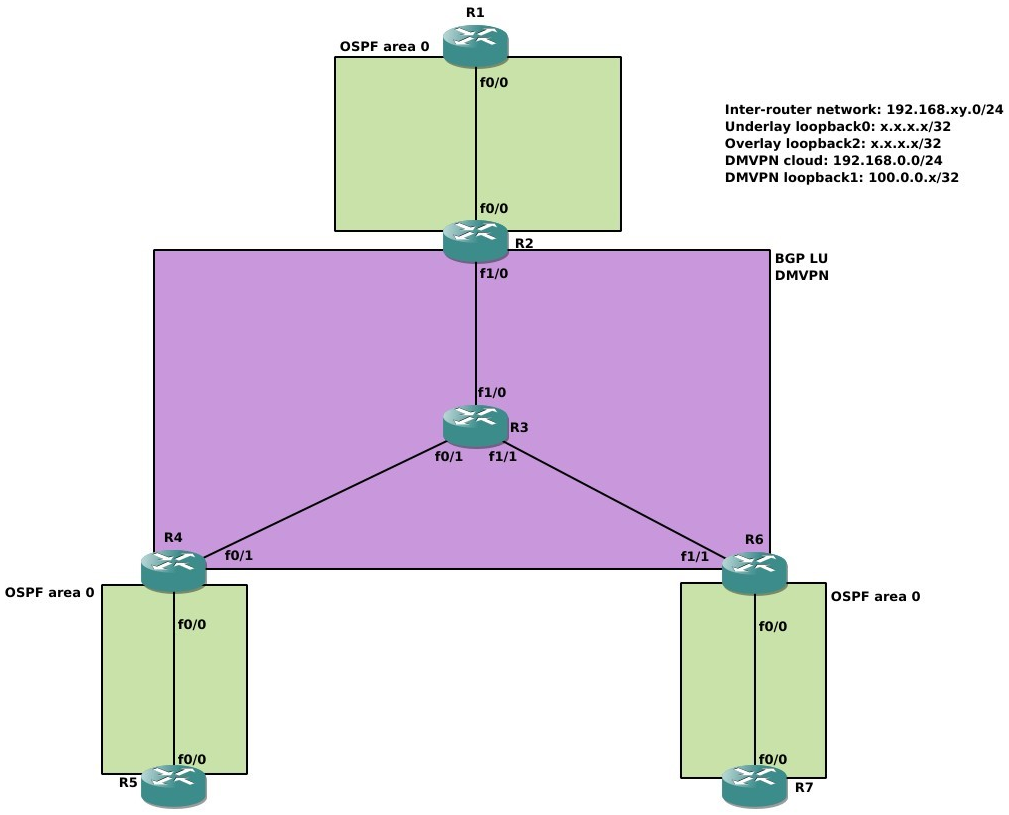
Роли маршрутизаторов:
- R1, R5, R7 (and R6 later) – MPLS PE;
- R3 – провайдер для DMVPN;
- R2 – DMVPN hub;
- R4, R6 – DMVPN spokes.
Протоколы маршрутизации:
- R1-R2, R4-R5, R6-R7 – OSPF на площадке организации;
- R3 – OSPF провайдера, обеспечивающий связность между маршрутизаторами DMVPN;
- R1, R5, R7 (R6) – MP-BGP VPNv4 AF;
- R2, R4, R6 – MP-BGP IPv4 AF;
Loopback0 отвечает за идентификацию маршрутизатора в сети, например, за назначение OSPF RID. Loopback1 является интерфейсом, с которого маршрутизаторы устанавливают BGP LU сессии; причины такой настройки рассмотрены далее в статье. Loopback2 эмулирует клиентские сети внутри VRF.
Начнём с базовой конфигурации PE:
R1(config)#vrf definition A
R1(config-vrf)#rd 1:1
R1(config-vrf)#address-family ipv4
R1(config-vrf-af)#route-target export 1:1
R1(config-vrf-af)#route-target import 1:1
R1(config-if)#interface Loopback0
R1(config-if)#ip address 1.1.1.1 255.255.255.255
R1(config)#interface Loopback2
R1(config-if)#vrf forwarding A
R1(config-if)#ip address 1.1.1.1 255.255.255.255
R1(config)#interface FastEthernet0/0
R1(config-if)#ip address 192.168.12.1 255.255.255.0
R1(config-if)#mpls ldp router-id Loopback0
R1(config)#router ospf 1
R1(config-router)#mpls ldp autoconfig
R1(config-router)#router-id 1.1.1.1
R1(config-router)#network 0.0.0.0 255.255.255.255 area 0
R1(config)#router bgp 1
R1(config-router)#template peer-policy L3VPN
R1(config-router-ptmp)#send-community both
R1(config-router-ptmp)#exit-peer-policy
R1(config-router)#template peer-session SESSION
R1(config-router-stmp)#remote-as 1
R1(config-router-stmp)#update-source Loopback0
R1(config-router-stmp)#exit-peer-session
R1(config-router)#bgp router-id 1.1.1.1
R1(config-router)#no bgp default ipv4-unicast
R1(config-router)#neighbor 5.5.5.5 inherit peer-session SESSION
R1(config-router)#neighbor 7.7.7.7 inherit peer-session SESSION
R1(config-router)#address-family vpnv4
R1(config-router-af)#neighbor 5.5.5.5 activate
R1(config-router-af)#neighbor 5.5.5.5 send-community extended
R1(config-router-af)#neighbor 5.5.5.5 inherit peer-policy L3VPN
R1(config-router-af)#neighbor 7.7.7.7 activate
R1(config-router-af)#neighbor 7.7.7.7 send-community extended
R1(config-router-af)#neighbor 7.7.7.7 inherit peer-policy L3VPN
R1(config-router-af)#exit-address-family
R1(config-router)#address-family ipv4 vrf A
R1(config-router-af)#redistribute connected
R1(config-router-af)#exit-address-family
R5(config)#vrf definition A
R5(config-vrf)# rd 1:1
R5(config-vrf)# address-family ipv4
R5(config-vrf-af)# route-target export 1:1
R5(config-vrf-af)# route-target import 1:1
R5(config-vrf-af)# exit-address-family
R5(config-vrf)#interface Loopback0
R5(config-if)# ip address 5.5.5.5 255.255.255.255
R5(config-if)#interface Loopback2
R5(config-if)# vrf forwarding A
R5(config-if)# ip address 5.5.5.5 255.255.255.255
R5(config-if)#interface FastEthernet0/0
R5(config-if)# ip address 192.168.45.5 255.255.255.0
R5(config-if)#mpls ldp router-id Loopback0
R5(config)#router ospf 1
R5(config-router)# mpls ldp autoconfig
R5(config-router)# router-id 5.5.5.5
R5(config-router)# network 0.0.0.0 255.255.255.255 area 0
R5(config-router)#router bgp 1
R5(config-router)# template peer-policy L3VPN
R5(config-router-ptmp)# send-community both
R5(config-router-ptmp)# exit-peer-policy
R5(config-router)# template peer-session SESSION
R5(config-router-stmp)# remote-as 1
R5(config-router-stmp)# update-source Loopback0
R5(config-router-stmp)# exit-peer-session
R5(config-router)# bgp router-id 5.5.5.5
R5(config-router)# no bgp default ipv4-unicast
R5(config-router)# neighbor 1.1.1.1 inherit peer-session SESSION
R5(config-router)# neighbor 7.7.7.7 inherit peer-session SESSION
R5(config-router)# address-family vpnv4
R5(config-router-af)# neighbor 1.1.1.1 activate
R5(config-router-af)# neighbor 1.1.1.1 send-community extended
R5(config-router-af)# neighbor 1.1.1.1 inherit peer-policy L3VPN
R5(config-router-af)# neighbor 7.7.7.7 activate
R5(config-router-af)# neighbor 7.7.7.7 send-community extended
R5(config-router-af)# neighbor 7.7.7.7 inherit peer-policy L3VPN
R5(config-router-af)# exit-address-family
R5(config-router)# address-family ipv4 vrf A
R5(config-router-af)# redistribute connected
R5(config-router-af)# exit-address-family
R7(config)#vrf definition A
R7(config-vrf)# rd 1:1
R7(config-vrf)# address-family ipv4
R7(config-vrf-af)# route-target export 1:1
R7(config-vrf-af)# route-target import 1:1
R7(config-vrf-af)# exit-address-family
R7(config-vrf)#interface Loopback0
R7(config-if)# ip address 7.7.7.7 255.255.255.255
R7(config-if)#interface Loopback2
R7(config-if)# vrf forwarding A
R7(config-if)# ip address 7.7.7.7 255.255.255.255
R7(config-if)#interface FastEthernet0/0
R7(config-if)# ip address 192.168.67.7 255.255.255.0
R7(config-if)#mpls ldp router-id Loopback0
R7(config)#router ospf 1
R7(config-router)# mpls ldp autoconfig
R7(config-router)# router-id 7.7.7.7
R7(config-router)# network 0.0.0.0 255.255.255.255 area 0
R7(config-router)#router bgp 1
R7(config-router)# template peer-policy L3VPN
R7(config-router-ptmp)# send-community both
R7(config-router-ptmp)# exit-peer-policy
R7(config-router)# template peer-session SESSION
R7(config-router-stmp)# remote-as 1
R7(config-router-stmp)# update-source Loopback0
R7(config-router-stmp)# exit-peer-session
R7(config-router)# bgp router-id 7.7.7.7
R7(config-router)# bgp log-neighbor-changes
R7(config-router)# no bgp default ipv4-unicast
R7(config-router)# neighbor 1.1.1.1 inherit peer-session SESSION
R7(config-router)# neighbor 5.5.5.5 inherit peer-session SESSION
R7(config-router)# address-family ipv4
R7(config-router-af)# exit-address-family
R7(config-router)# address-family vpnv4
R7(config-router-af)# neighbor 1.1.1.1 activate
R7(config-router-af)# neighbor 1.1.1.1 send-community extended
R7(config-router-af)# neighbor 1.1.1.1 inherit peer-policy L3VPN
R7(config-router-af)# neighbor 5.5.5.5 activate
R7(config-router-af)# neighbor 5.5.5.5 send-community extended
R7(config-router-af)# neighbor 5.5.5.5 inherit peer-policy L3VPN
R7(config-router-af)# exit-address-family
R7(config-router)# address-family ipv4 vrf A
R7(config-router-af)# redistribute connected R7(config-router-af)# exit-address-family
Следующий шаг – подключить DMVPN маршрутизаторы к локальным сегментам сети:
R2(config)#interface Loopback0
R2(config-if)# ip address 2.2.2.2 255.255.255.255
R2(config-if)#interface FastEthernet0/0
R2(config-if)# ip address 192.168.12.2 255.255.255.0
R2(config-if)#mpls ldp router-id Loopback0
R2(config)#router ospf 1
R2(config-router)# mpls ldp autoconfig
R2(config-router)# router-id 2.2.2.2
R2(config-router)# redistribute bgp 1 subnets
R2(config-router)# passive-interface default
R2(config-router)# no passive-interface FastEthernet0/0
R2(config-router)# no passive-interface Loopback0
R2(config-router)# network 0.0.0.0 255.255.255.255 area 0
R4(config)#interface Loopback0
R4(config-if)# ip address 4.4.4.4 255.255.255.255
R4(config-if)#interface FastEthernet0/0
R4(config-if)# ip address 192.168.45.4 255.255.255.0
R4(config-if)#mpls ldp router-id Loopback0
R4(config)#router ospf 1
R4(config-router)# mpls ldp autoconfig
R4(config-router)# router-id 4.4.4.4
R4(config-router)# redistribute bgp 1 subnets
R4(config-router)# passive-interface default
R4(config-router)# no passive-interface FastEthernet0/0
R4(config-router)# no passive-interface Loopback0
R4(config-router)# network 0.0.0.0 255.255.255.255 area 0
R6(config)#interface Loopback0
R6(config-if)# ip address 6.6.6.6 255.255.255.255
R6(config-if)#interface FastEthernet0/0
R6(config-if)# ip address 192.168.67.6 255.255.255.0
R6(config-if)#mpls ldp router-id Loopback0
R6(config)#router ospf 1
R6(config-router)# mpls ldp autoconfig
R6(config-router)# redistribute bgp 1 subnets
R6(config-router)# passive-interface default
R6(config-router)# no passive-interface FastEthernet0/0
R6(config-router)# no passive-interface Loopback0
R6(config-router)# network 0.0.0.0 255.255.255.255 area 0
Наконец последний этап подготовки к рассмотрению BGP LU – настройка DMVPN. В статье использован подход front-door VRF, чтобы уменьшить объём посторонней информации в глобальной таблице маршрутизации:
R3(config)#interface Loopback0
R3(config-if)# ip address 3.3.3.3 255.255.255.255
R3(config-if)#interface FastEthernet0/1
R3(config-if)# ip address 192.168.34.3 255.255.255.0
R3(config-if)#interface FastEthernet1/0
R3(config-if)# ip address 192.168.23.3 255.255.255.0
R3(config-if)#interface FastEthernet1/1
R3(config-if)# ip address 192.168.36.3 255.255.255.0
R3(config-if)#router ospf 1
R3(config-router)# router-id 3.3.3.3
R3(config-router)# network 0.0.0.0 255.255.255.255 area 0
R2(config)#vrf definition FVRF
R2(config-vrf)# rd 1:1
R2(config-vrf)# address-family ipv4
R2(config-vrf-af)# exit-address-family
R2(config-vrf)#interface Tunnel0
R2(config-if)# ip address 192.168.0.2 255.255.255.0
R2(config-if)# no ip redirects
R2(config-if)# ip nhrp map multicast dynamic
R2(config-if)# ip nhrp network-id 1
R2(config-if)# ip nhrp redirect
R2(config-if)# tunnel source FastEthernet1/0
R2(config-if)# tunnel mode gre multipoint
R2(config-if)# tunnel vrf FVRF
R2(config-if)#interface FastEthernet1/0
R2(config-if)# vrf forwarding FVRF
R2(config-if)# ip address 192.168.23.2 255.255.255.0
R2(config-if)#router ospf 2 vrf FVRF
R2(config-router)# router-id 192.168.23.2
R2(config-router)# network 0.0.0.0 255.255.255.255 area 0
R4(config)#vrf definition FVRF
R4(config-vrf)# rd 1:1
R4(config-vrf)# address-family ipv4
R4(config-vrf-af)# exit-address-family
R4(config-vrf)#interface Tunnel0
R4(config-if)# ip address 192.168.0.4 255.255.255.0
R4(config-if)# no ip redirects
R4(config-if)# ip nhrp network-id 1
R4(config-if)# ip nhrp nhs 192.168.0.2 nbma 192.168.23.2 multicast
R4(config-if)# ip nhrp shortcut
R4(config-if)# tunnel source FastEthernet0/1
R4(config-if)# tunnel mode gre multipoint
R4(config-if)# tunnel vrf FVRF
R4(config-if)#interface FastEthernet0/1
R4(config-if)# vrf forwarding FVRF
R4(config-if)# ip address 192.168.34.4 255.255.255.0
R4(config-if)#router ospf 2 vrf FVRF
R4(config-router)# router-id 192.168.34.4
R4(config-router)# network 0.0.0.0 255.255.255.255 area 0
R6(config)#vrf definition FVRF
R6(config-vrf)# rd 1:1
R6(config-vrf)# address-family ipv4
R6(config-vrf-af)# exit-address-family
R6(config-vrf)#interface Tunnel0
R6(config-if)# ip address 192.168.0.6 255.255.255.0
R6(config-if)# no ip redirects
R6(config-if)# ip nhrp network-id 1
R6(config-if)# ip nhrp nhs 192.168.0.2 nbma 192.168.23.2 multicast
R6(config-if)# ip nhrp shortcut
R6(config-if)# tunnel source FastEthernet1/1
R6(config-if)# tunnel mode gre multipoint
R6(config-if)# tunnel vrf FVRF
R6(config-if)#interface FastEthernet1/1
R6(config-if)# vrf forwarding FVRF
R6(config-if)# ip address 192.168.36.6 255.255.255.0
R6(config-if)#router ospf 2 vrf FVRF
R6(config-router)# network 0.0.0.0 255.255.255.255 area 0
Время заняться делом. Необходимым условием для L3VPN является наличие рабочего LSP между PE. Поскольку ни LDP, ни RSVP в рамках DMVPN для этой задачи не подходят, используем MP-BGP для передачи следующей информации:
- адреса loopback;
- соответствующие им MPLS метки.
Звучит довольно просто. Что насчёт поддержки MPLS на интерфейсах?
R2#sho mpls interfaces
Interface IP Tunnel BGP Static Operational
FastEthernet0/0 Yes (ldp) No No No Yes
На Tunnel0 MPLS пока не работает. Нам нужно разрешить только поддержку MPLS пакетов, не включая LDP, поэтому команда “mpls ip” не подходит. Впрочем, существует ещё одна менее известная команда, отвечающая нашей задаче:
R2(config)#interface Tunnel0
R2(config-if)#mpls bgp forwarding
R2#sho mpls interfaces
Interface IP Tunnel BGP Static Operational
FastEthernet0/0 Yes (ldp) No No No Yes
Tunnel0 No No Yes No Yes
После выполнения этой команды на всех spoke можно приступать к настройке BGP. В этой статье мы используем iBGP между hub и spoke; hub выполняет роль route-reflector и принимает входящие BGP-соединения:
R2(config)#router bgp 1
R2(config-router)# bgp router-id 2.2.2.2
R2(config-router)# bgp listen range 192.168.0.0/24 peer-group DMVPN
R2(config-router)# no bgp default ipv4-unicast
R2(config-router)# neighbor DMVPN peer-group
R2(config-router)# neighbor DMVPN remote-as 1
R2(config-router)# neighbor DMVPN update-source Tunnel0
R2(config-router)# address-family ipv4
R2(config-router-af)# network 1.1.1.1 mask 255.255.255.255
R2(config-router-af)# neighbor DMVPN activate
R2(config-router-af)# neighbor DMVPN route-reflector-client
R2(config-router-af)# neighbor DMVPN send-label
R4(config)#router bgp 1
R4(config-router)# bgp router-id 4.4.4.4
R4(config-router)# no bgp default ipv4-unicast
R4(config-router)# neighbor 192.168.0.2 remote-as 1
R4(config-router)# neighbor 192.168.0.2 update-source Tunnel0
R4(config-router)# address-family ipv4
R4(config-router-af)# network 5.5.5.5 mask 255.255.255.255
R4(config-router-af)# neighbor 192.168.0.2 activate
R4(config-router-af)# neighbor 192.168.0.2 send-label
R6(config)#router bgp 1
R6(config-router)# bgp router-id 6.6.6.6
R6(config-router)# no bgp default ipv4-unicast
R6(config-router)# neighbor 192.168.0.2 remote-as 1
R6(config-router)# neighbor 192.168.0.2 update-source Tunnel0
R6(config-router)# address-family ipv4
R6(config-router-af)# network 7.7.7.7 mask 255.255.255.255
R6(config-router-af)# neighbor 192.168.0.2 activate
R6(config-router-af)# neighbor 192.168.0.2 send-label
Проверим, есть ли IP-связность между PE:
R5#ping 1.1.1.1 so lo 0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 1.1.1.1, timeout is 2 seconds:
Packet sent with a source address of 5.5.5.5 !!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 48/57/64 ms
Достаточно ли этого для связности внутри VRF?
R5#ping vrf A 1.1.1.1 so lo 0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 1.1.1.1, timeout is 2 seconds:
Packet sent with a source address of 5.5.5.5
.....
Success rate is 0 percent (0/5)
К сожалению, решение несколько сложнее, чем могло бы показаться на первый взгляд. Причина отсутствия связности – нерабочий LSP между PE:
R5#ping mpls ipv4 1.1.1.1/32 source 5.5.5.5
Sending 5, 100-byte MPLS Echos to 1.1.1.1/32, timeout is 2 seconds, send interval is 0 msec:
Codes: '!' - success, 'Q' - request not sent, '.' - timeout,
'L' - labeled output interface, 'B' - unlabeled output interface,
'D' - DS Map mismatch, 'F' - no FEC mapping, 'f' - FEC mismatch,
'M' - malformed request, 'm' - unsupported tlvs, 'N' - no label entry,
'P' - no rx intf label prot, 'p' - premature termination of LSP,
'R' - transit router, 'I' - unknown upstream index, 'X' - unknown return code, 'x' - return code 0
Type escape sequence to abort.
BBBBB Success rate is 0 percent (0/5)
Если быть точным, место отказа – R4:
R4#sho mpls forwarding-table 1.1.1.1 32
Local Outgoing Prefix Bytes Label Outgoing Next Hop
Label Label or Tunnel Id Switched interface
19 No Label 1.1.1.1/32 1125 Tu0 192.168.0.2
Впрочем, является ли R4 местом возникновения проблемы? Разве R2 не должен был послать R4 префикс вместе с меткой?
R4#sho ip bgp labels
Network Next Hop In label/Out label
1.1.1.1/32 192.168.12.1 nolabel/nolabel
2.2.2.2/32 192.168.0.2 nolabel/imp-null
<output omitted>
<output omitted>

OSFP, будучи link-state протоколом, исключает петли в топологии за счёт построения дерева кратчайшего пути в рамках одной зоны с помощью алгоритма Дейкстры. Однако поведение OSPF между зонами напоминает скорее поведение distance-vector протоколов, которые обмениваются всего лишь префиксами и соответствующими метриками без каких-либо данных о фактической топологии; по этой причине некоторые авторы могут называть OSPF гибридным протоколом маршрутизации. Механизм защиты от петель маршрутизации между зонами, однако, довольно прост: все зоны должны обмениваться маршрутной информацией через backbone зону, зону 0, прямой обмен маршрутами между зонами невозможен.
Впрочем, тёмный гений изобрёл инструмент разрушения стройной идеи OSPF – речь о функции OSPF Virtual Link (VL). Даже маленькие инженеры знают, что использовать VL – плохая затея; все согласны с тем, что VL оправдан только в крайних случаях для временного и быстрого исправления критичной ситуации. Однако обнаружить подробное объяснение, чем же именно VL так плох помимо дополнительного уровня сложности, оказалось не так-то просто. Сложность инженерам не помеха, поэтому давайте поищем более весомые аргументы против VL.
Нет ничего лучше чашки кофе с утра, рабочей лабы и широкополосного доступа к google.com. Для эмуляции топологии в GNS3 были использованы образы Cisco 7200:
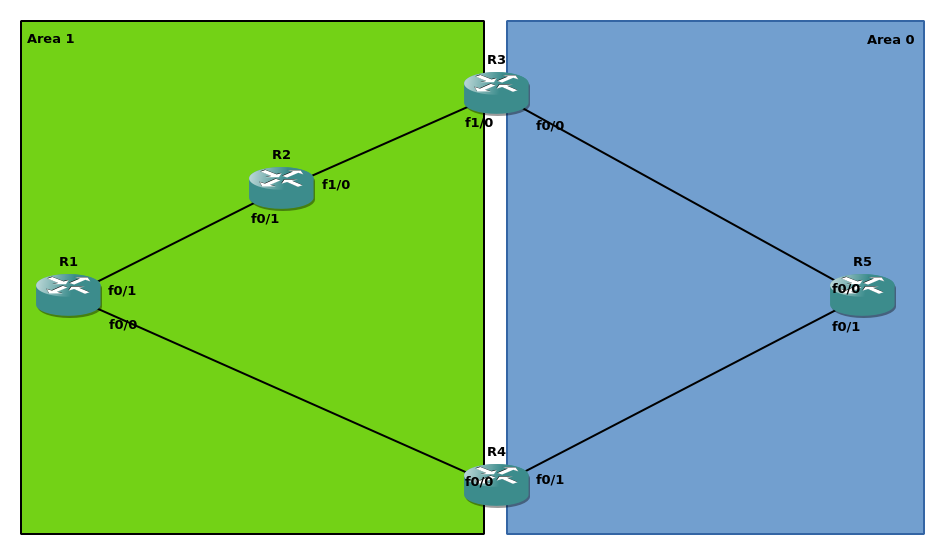
На каждом маршрутизаторе в соответствующей зоне настроен виртуальный интерфейс (loopback0) для назначения OSPF RID и других инфраструктурных задач; loopback на ABR находятся в зоне 0. Схема адресации: 192.168.xy.x|y/24 для соединения Rx и Ry (например, 192.168.12.1 на интерфейсе f0/1 R1). Помимо штатной настройки OSPF, между R1 и R3 создан VL.
Если у читателя много свободного времени, можно убедиться в доступности всех префиксов из любой точки сети; я же сконцентрируюсь на связности R1 и R5:
R1#ping 5.5.5.5 so lo 0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 5.5.5.5, timeout is 2 seconds:
Packet sent with a source address of 1.1.1.1
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 20/30/40 ms
R1#traceroute 5.5.5.5 so lo 0 numeric
Type escape sequence to abort.
Tracing the route to 5.5.5.5
VRF info: (vrf in name/id, vrf out name/id)
1 192.168.14.4 16 msec 24 msec 20 msec
2 192.168.45.5 48 msec 16 msec 24 msec
Трафик следует по кратчайшему маршруту, как и задумывалось. Перейдем к гвоздю сегодняшней программы:
R1(config)#router os 1
R1(config-router)#no capability transit
Transit area capability – это способность OSPFv2 выбрать более оптимальный маршрут для трафика, следующего по VL. Идея довольно проста: необходимо взять префикс, доступный через VL, и сравнить его с имеющимися LSA3; если найдено полное совпадение и маршрут через LSA3 оптимальнее, то следует использовать оптимальный маршрут. OSPFv1 не обладал такой функцией, и весь трафик следовал по тому же пути, что и VL. Если читатель хочет глубже погрузиться в данную тему, могу порекомендовать статью Петра Лапухова. А мы продолжаем:
R1#traceroute 5.5.5.5 so lo 0 n
Type escape sequence to abort.
Tracing the route to 5.5.5.5
VRF info: (vrf in name/id, vrf out name/id)
1 192.168.12.2 44 msec 16 msec 20 msec
2 192.168.23.3 20 msec 40 msec 40 msec
3 192.168.35.5 76 msec 44 msec 44 msec
Изменения есть, но они некритичны: теперь R1 выбирает путь вдоль VL в полном соответствии с поведением OSPFv1 без transit capability. Где же обещанная петля? Добавим нашей топологии некоторой пикантности:
| R2 | R3 |
| R2(config)#int f1/0 R2(config-if)#ip os cost 100 |
R3(config)#int f1/0 R3(config-if)#ip os cost 100 |
Ухудшили плохой маршрут, и что с того?
R1#traceroute 5.5.5.5 so lo 0 n
Type escape sequence to abort.
Tracing the route to 5.5.5.5
VRF info: (vrf in name/id, vrf out name/id)
1 192.168.12.2 20 msec 16 msec 16 msec
2 192.168.12.1 24 msec 16 msec 16 msec
3 192.168.12.2 36 msec 32 msec 44 msec
4 192.168.12.1 28 msec 36 msec 40 msec
5 192.168.12.2 44 msec 48 msec 64 msec
6 192.168.12.1 60 msec 60 msec 60 msec
7 192.168.12.2 80 msec 80 msec 80 msec
8 192.168.12.1 84 msec 76 msec 76 msec
Дамы и господа, это – петля. Теперь взглянем на проделанную работу:
- VL между R1-R3;
- Transit capability отключена;
- Метрика R2-R3 увеличена.
Последний пункт стоит отметить особо: в результате изменения метрики R1 является next-hop для 5.5.5.5/32 с точки зрения R2:
R2#sho ip ro 5.5.5.5 255.255.255.255 longer-prefixes
5.0.0.0/32 is subnetted, 1 subnets
O IA 5.5.5.5 [110/4] via 192.168.12.1, 00:06:21, FastEthernet0/1
Выбор маршрута с точки зрения R2 выглядит довольно естественно; выбор R1 же может показаться странным на первый взгляд:
R1#sho ip ro 5.5.5.5 255.255.255.255 longer-prefixes
5.0.0.0/32 is subnetted, 1 subnets
O 5.5.5.5 [110/103] via 192.168.12.2, 00:08:07, FastEthernet0/1
Однако такое поведение вполне соответствует правилам выбора маршрута в OSPFv1:
- 5.5.5.5/32 доступен через VL в зоне 0;
- трафик следует по тому же пути, что и VL.
R2 ничего не знает ни про VL, ни про transit area; он всего ли маршрутизирует пакеты согласно таблице маршрутизации, построенной на основе LSA3.
На данном этапе может показаться, что причина всех бед – transit capability, а не VL. Впрочем, разрешается этот вопрос довольно просто: подобная проблема была обнаружена в OSPFv1 и решена в OSPFv2 посредством transit area. Читатель может заметить, что описанное поведение родственно по природе микропетлям, возникающим в ходе перестроения дерева, и с ним трудно не согласиться. Впрочем, разница есть и существенная: микропетли представляют собой переходное состояние. тогда как петли из-за VL в OSPFv1 носили постоянный характер.
Немного английского оригинала из OSPFv2 RFC про отличия от OSPFv1:
“When summarizing information into a virtual link's transit area, version 2 of the OSPF specification prohibits the collapsing of multiple backbone IP networks/subnets into a single summary link.”
Проблема, завуалированная авторами RFC в этой фразе, очень похожа по характеру на рассматриваемую в статье. Если бы маршруты зоны 0 можно было бы суммаризовать на ABR, то полученный префикс в LSA3 не смог бы быть использован маршрутизатором с VL. Передача трафика была бы нарушена вследствие разного представления о топологии маршрутизаторами зоны:
- Маршрутизатор с VL выбрал бы маршрут из зоны 0; из-за отсутствия точно совпадающего LSA3 был бы выбран путь вдоль VL;
- Остальные же маршрутизаторы использовали бы суммарный маршрут из LSA3.
В нашем случае, если бы R3 суммаризовал маршрут до 5.5.5.0/24, то R2 выбрал бы более точный маршрут 5.5.5.0/25 через R4, что привело бы к петле маршрутизации. Решение? Нужно обеспечить всем маршрутизаторам зоны равный доступ к маршрутной информации из зоны 0, запретив изменение последней, т.е. суммаризацию. Стоит отметить, что это не относится к маршрутам из других зон, поскольку эти суммарные маршруты будут одинаковы как в зоне 0, так и других зонах; только ABR зоны-источника могут суммаризовать информацию о топологии из LSA1/2 в простой LSA3. Более того, запрещена только суммаризация префиксов из зоны 0, фильтрация же не ограничена. Последняя не изменяет сам префикс; в результате у маршрутизаторов зоны будет меньше пар LSA1-LSA3 для выбора более оптимального маршрута, что не может привести к описанной в статье проблеме.
Вывод: некоторые малоизвестные настройки по умолчанию лучше не трогать.
P.S. Существует не менее интересный способ выстрелить себе в ногу.
Страница 1 из 8